
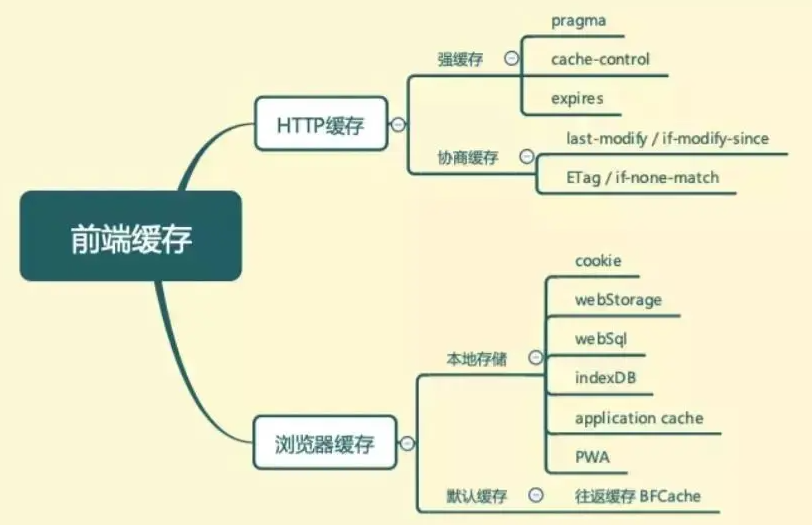
前端缓存技术
web 缓存技术主要分为 HTTP 缓存和浏览器缓存
HTTP 缓存是在 HTTP 请求传输时用到的缓存,主要在服务器代码上设置,是 web 缓存的核心
浏览器缓存在前端项目上进行设置
为什么需要缓存
在讨论 HTTP 缓存和浏览器缓存前,我们先来说一下,为什么需要缓存,缓存到底能解决什么问题?
- 减少不必要的网络传入,节省带宽
- 加载更快
- 减轻服务器负载
- 但是占用内存
所以,缓存是为了加速页面加载、减轻服务器压力而存在的
HTTP 缓存
参考链接:https://blog.csdn.net/wuliyouMaozhi/article/details/126455241
强缓存
废弃 Expires
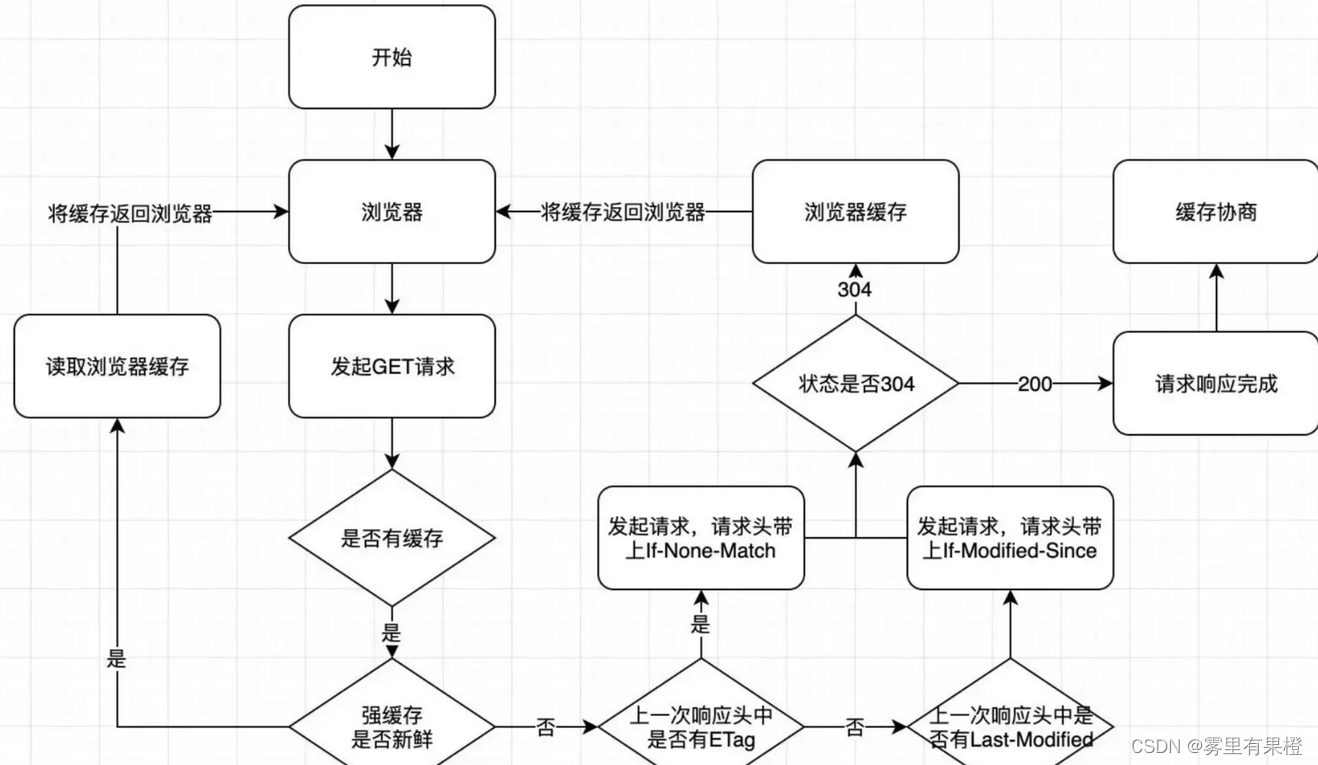
从强制缓存的角度触发,如果浏览器判断请求的目标资源有效命中强缓存,如果命中,则可以直接从内存中读取目标资源,无需与服务器做任何通讯
以前,我们通常使用响应头的 Expires 字段去实现强缓存。但是现在 Expires 已经被废弃了,因为 Expires 判断强缓存是否过期的机制是:获取本地时间戳,并对先前拿到的资源文件中的 Expires 字段的时间做比较
这种过度依赖本地时间的做法,如果本地与服务器时间不同步,就会出现资源无法被缓存或者资源永远被缓存的情况
所以现在我们并不推荐使用 Expires,强缓存功能通常使用 cache-control 字段来代替 Expires 字段
Cache-control
Cache-control 这个字段在 http1.1 中被增加,Cache-control 完美解决了 Expires 本地时间和服务器时间不同步的问题
//往响应头中写入需要缓存的时间
res.writeHead(200,{
'Cache-Control':'max-age=10'
});
Cache-Control:max-age=N,N 就是需要缓存的秒数。从第一次请求资源的时候开始,往后 N 秒内,资源若再次请求,则直接从磁盘(或内存中读取),不与服务器做任何交互
Cache-control 有 max-age、s-maxage、no-cache、no-store、private、public 这六个属性
- max-age 决定客户端资源被缓存多久。
- s-maxage 决定代理服务器缓存的时长。
- no-cache 表示是强制进行协商缓存。
- no-store 是表示禁止任何缓存策略。
- public 表示资源即可以被浏览器缓存也可以被代理服务器缓存。
- private 表示资源只能被浏览器缓存。
协商缓存
基于 last-modified 的协商缓存
- 首先需要在服务器端读出文件修改时间
- 将读出来的修改时间赋给响应头的 last-modified 字段
- 最后设置 Cache-control:no-cache
const { mtime } = fs.statSync('./img.png') // 读取文件的最新修改事件
res.setHeader('last-modified', mtime.toUTCString())) // 设置文件最后修改时间
res.setHeader('Cache-Control', 'no-cache') //设置no-cache
服务端如此操作之后,还没结束。当客户端读取到 last-modified 的时候,会在下次的请求标头中携带一个字段:If-Modified-Since

而这个请求头中的 If-Modified-Since 就是服务器第一次修改时给的时间
那么之后每次对该资源的请求,都会带上 If-Modified-Since 这个字段,而服务端就需要拿到这个时间并再次读取该资源的修改时间,让他们两个做一个比对来决定是读取缓存还是返回新的资源
因为该方式是基于文件对比修改时间来判断缓存的,所以也有两个漏洞问题:
- 根据文件修改时间来判断,所以,在文件内容本身不修改的情况下,依然有可能更新文件修改时间(修改文件名再改回来这种),这样缓存也会失效
- 文件在毫秒级别时间内完成修改,因为 last-modified 的记录最小单位是秒,所以文件修改时间不会变,不会返回新文件
基于 ETag 的协商缓存
http1.1 为了避开上面时间戳比较形式的缓存问题,加入了 ETag 的协商缓存,修改成了比较文件指纹
文件指纹:根据文件内容计算出唯一哈希值。文件内容一旦改变则指纹改变
流程是这样的:
- 第一次请求某资源的时候,服务端读取文件并计算出文件指纹,将文件指纹放在响应头的 etag 字段中跟资源一起返回给客户端
- 第二次请求某资源的时候,客户端自动从缓存中读取出上一次服务端返回的 ETag 也就是文件指纹。并赋给请求头的 if-None-Match 字段,让上一次的文件指纹跟随请求一起回到服务端
- 服务端拿到请求头中的 is-None-Match 字段值(也就是上一次的文件指纹),并再次读取目标资源并生成文件指纹,两个指纹做对比。如果两个文件指纹完全吻合,说明文件没有被改变,则直接返回 304 状态码和一个空的响应体并 return。如果两个文件指纹不吻合,则说明文件被更改,那么将新的文件指纹重新存储到响应头的 ETag 中并返回给客户端
当然,如此准确的缓存校验也有缺点:
- ETag 需要计算文件指纹,这样意味着,服务端需要更多的计算开销。如果文件尺寸大数量多,并且计算频繁,那么 ETag 的计算就会影响服务器性能。这样的场景就不再适合 ETag
- ETag 有强验证和弱验证。强验证指哈希码深入到每一个字节,保证文件内容绝对的不变,但也非常消耗计算量;弱验证是提取部分属性生成哈希码,整体速度略快但准确率不搞,会降低协商缓存的有效性
总结
- http 缓存可以减少宽带流量,加快响应速度
- 关于强缓存,cache-control 是 Expires 的完全替代方案,在可以使用 cache-control 的情况下不要使用 expires
- 关于协商缓存,etag 并不是 last-modified 的完全替代方案,而是补充方案,具体用哪一个,取决于业务场景
- 有些缓存是从磁盘读取,有些缓存是从内存读取,有什么区别?答:从内存读取的缓存更快
- 所有带 304 的资源都是协商缓存,所有标注(从内存中读取/从磁盘中读取)的资源都是强缓存
浏览器缓存
cookie
主要用于存储用户信息,它的内容可以主动在请求时传递给服务器。
它是浏览器提供的一种将 document 对象的 cookie 属性提供给 js 的机制,可以由 js 对其进行控制。
cookie 存于用户硬盘的一个文件,通常对应于一个域名,当浏览器再次访问这个域名便让这个 cookie 可被使用。
因此 cookie 可以跨域,一个域名下多个网页,但不能跨多个域名使用。
cookie 的结构简单来说是以键值对的形式保存,即 key = value 的格式,每个 cookie 间使用“;”隔开。
它最大的一个优点便是将信息存储于用户硬盘,因此可以作为全局变量,这是它常用的几种场合:
保存用户登录状态
跟踪用户行为
定制页面
创建购物车,例如淘宝网就使用 cookie 记录了用户曾经浏览过的商品,方便随时进行比较,而 cookie 的缺点主要集中于安全性和隐私保护。
主要包括以下几种:
cookie 可能被禁用。当用户非常注重个人隐私保护时,他很有可能禁用浏览器的 cookie 功能。
cookie 是与浏览器相关的。这意味着即使访问的是同一个页面,不同浏览器之间所保存的 cookie 也是不能互相访问的。
cookie 可能被删除。因为每个 cookie 都是硬盘上的一个文件,因此很有可能被用户删除。
cookie 安全性不够高。所有的 cookie 都是以纯文本的形式记录于文件中,因此如果要保存用户名密码等信息时,最好事先经过加密处理
容量过小,只允许容纳 4 KB。
localStorage
在 HTML5 中,新增了 localStorage 主要作为本地存储,以 5 MB 的内存大小,解决了 cookie 存储空间 4 KB 的问题。
且保存的数据将一直被保存于浏览器中,直到用户清除浏览器缓存数据为止。
localStorage 的优势与劣势:
相比 cookie 节省带宽、容量更大
目前所有浏览器中都会把 localStorage 的值限定为 序列化的 string 格式
在浏览器隐私模式下不可读取
无法被网络爬虫捕捉
sessionStorage
sessionStorage 的其他属性与 localStorage 相同,不过它的生命周期与标签页相同,当标签页被关闭时,sessionStorage 也会被清除
大容量存储
webSql(已被废弃)和 indexDB 主要用于前端又大容量存储需求的页面上,比如在线编辑浏览器或者网页邮箱
| 存储方式 | 介绍 | 容量 | 状态 |
|---|---|---|---|
| webSql | 关系型数据库 | 50MB | 废弃 |
| indexDB | 非关系型数据库 | 50MB | 正常使用 |
下面主要讲一讲 indexDB,它具有以下特点
- 键值对储存。 IndexedDB 内部采用对象仓库(object store)存放数据。所有类型的数据都可以直接存入,包括 JavaScript 对象。对象仓库中,数据以“键值对”的形式保存,每一个数据记录都有对应的主键,主键是独一无二的,不能有重复,否则会抛出一个错误。
- 异步。 IndexedDB 操作时不会锁死浏览器,用户依然可以进行其他操作,这与 LocalStorage 形成对比,后者的操作是同步的。异步设计是为了防止大量数据的读写,拖慢网页的表现。
- 支持事务。 IndexedDB 支持事务(transaction),这意味着一系列操作步骤之中,只要有一步失败,整个事务就都取消,数据库回滚到事务发生之前的状态,不存在只改写一部分数据的情况。
- 同源限制。 IndexedDB 受到同源限制,每一个数据库对应创建它的域名。网页只能访问自身域名下的数据库,而不能访问跨域的数据库。
- 储存空间大。 IndexedDB 的储存空间比 LocalStorage 大得多,一般来说不少于 250MB,甚至没有上限。
- 支持二进制储存。 IndexedDB 不仅可以储存字符串,还可以储存二进制数据(ArrayBuffer 对象和 Blob 对象)。
后续 API 及操作较为繁琐,不再赘述,详见:https://blog.csdn.net/qq_41581588/article/details/124744083
PWA
PWA 即渐进式网络应用,主要目标是实现 web 网站的 APP 式功能和展示。
PWA 用 manifest 构建了自己的 APP 骨架,用 ServiceWorker 来控制缓存的使用
Manifest 就是一个 json 文件,在里面给出了诸如主题、背景色、图标等一系列的描述,用来让 Web 应用更接近于原生应用
{
"name": "Progressive Times web app",
"short_name": "Progressive Times",
"start_url": "/index.html",
"display": "standalone",
"theme_color": "#FFDF00",
"background_color": "#FFDF00",
"icons": [
{
"src": "homescreen.png",
"sizes": "192x192",
"type": "image/png"
},
{
"src": "homescreen-144.png",
"sizes": "144x144",
"type": "image/png"
}
]
}
- name、short_name:指定了 Web App 的名称。short_name 其实是该应用的一个简称。一般来说,当没有足够空间展示应用的 name 时,系统就会使用 short_name。
- start_url:这个属性指定了用户打开该 Web App 时加载的 URL。相对 URL 会相对于 Manifest。这里我们指定了 start_url 为 index.html,访问 index 文件。
- display:控制了应用的显示模式,它有四个值可以选择:fullscreen 、standalone 、minimal-ui 和 browser
- fullscreen:全屏显示,会尽可能将所有的显示区域都占满。
- standalone:独立应用模式,这种模式下打开的应用有自己的启动图标,并且不会有浏览器的地址栏。因此看起来更像一个 Native App。
- minimal-ui:与 standalone 相比,该模式会多出地址栏。
- browser:一般来说,会和正常使用浏览器打开样式一致。
- orientation:控制 Web App 的方向。设置某些值会具有类似锁屏的效果(禁止旋转)
- landscape-primary:当视窗宽度大于高度时,当前应用处于“横屏”状态。
- landscape-secondary:landscape-primary 的 180° 方向。
- landscape:根据屏幕的方向,自动横屏幕 180° 切换。
- portrait-primary:当视窗宽度小于高度时,当前应用处于“竖屏”状态。
- portrait-secondary:portrait-primary 的 180° 方向。
- portrait:根据屏幕方向,自动竖屏 180° 切换。
- natural:根据不同平台的规则,显示为当前平台的 0° 方向。
- any:任意方向切换。
- icons、background_color:icons 用来指定应用的桌面图标
- sizes:图标的大小。通过指定大小,系统会选取最合适的图标展示在相应位置上。
- src:图标的文件路径。注意相对路径是相对于 Manifest。
- type:图标的图片类型。
- background_color 是在应用的样式资源加载完毕前的默认背景,因此会展示在开屏界面。background_color 加上我们刚才定义的 icons 就组成了 Web App 打开时的“开屏图”
- theme_color:定义应用程序的默认主题颜色。这有时会影响操作系统显示应用程序的方式(例如,在 Android 的任务切换器上,主题颜色包围应用程序)
在 html 中引入
<html>
<head>
...
<link rel="manifest" href="/manifest.json" />
</head>
</html>
实现了缓存策略的 ServiceWorker 的情况详见:ServiceWorker
往返缓存
往返缓存又称为 BFCache,是浏览器在前进后退按钮上为了提升历史页面的渲染速度的一种策略
该策略具体表现为,当用户前往新页面时,将当前页面的浏览器 DOM 状态保存到 BFCache 中;当用户点击后退按钮的时候,将页面直接从 BFCache 中加载,节省了网络请求的时间。